Designing an enterprise solution architecture for ML / AI / GenAI use cases
Introduction
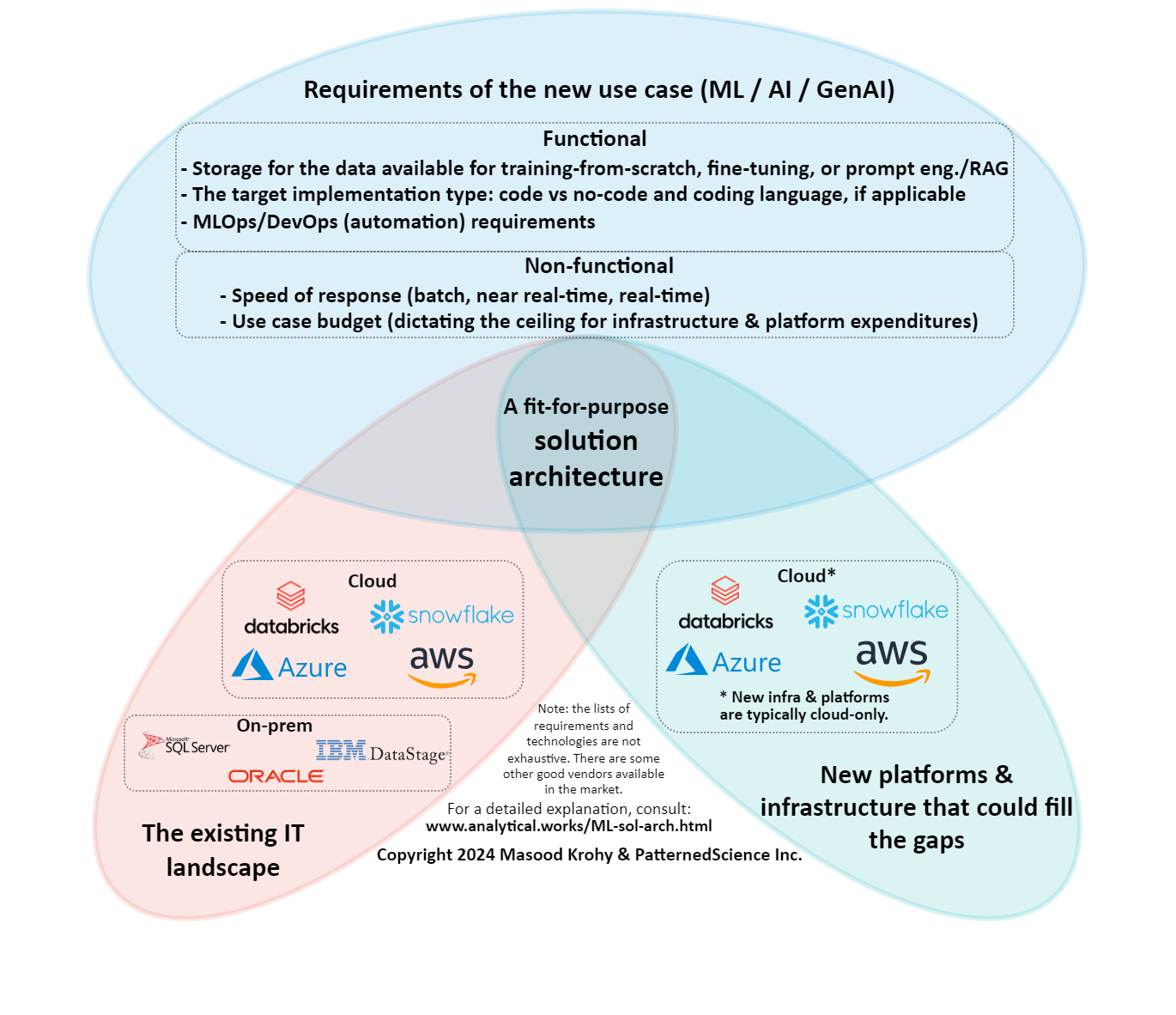
Designing a fit-for-purpose solution architecture at an enterprise requires consideration of the following three elements:
- Requirements specific to the new use case (ML / AI / GenAI)
- The existing IT architecture landscape
- New candidate platforms and infrastructure that could help fill the gaps
This short article highlights the importance of identifying the intersection among the three elements so that one ends up with a solution architecture that meets the need of the new use case, uses as much as possible components from the existing IT architecture landscape and fills the gaps with tools, platforms or infrastructure that are needed to be brought in to arrive at a viable, working solution architecture.